Tiempo estimado de lectura < 5 min
El otro día en el trabajo tenía que comparar dos fuentes de datos que presentaban un formato diferente a nivel tabular. Puesto que ambas fuentes tenían algunas deficiencias (de continente, no contenido), decidí escribir dos programas en R para convertirlas en tablas estructuralmente idénticas.
AVISO: Si quieres saltarte la cháchara, baja hasta la función…
EL PROBLEMA
El “problema” surgió cuando, a lo largo del proceso, me encontré con una lista compuesta por más de 40.000 pequeños conjuntos de datos, todos ellos con las mismas variables y mismo número de filas, aproximadamente 20.
El siguiente paso era convertir esa lista de conjuntos de datos data.frame en un gran conjunto, para lo cual utilicé el funcional Reduce, pasándole la función rbind junto con la lista de data.frames. Pero… no terminaba. Pasaban horas y no terminaba.
LA IDEA
Comprobé que el Reduce estaba haciendo su trabajo, para lo que tomé 100, 200, 500 y 1000 elementos de la lista… y funcionaba. Pero, además, me di cuenta de que para 200 no tardaba el doble que para 100, y que para 1000 tardaba mucho más que si hacía para 100 diez veces. El tiempo que invierte Reduce no es proporcional, lo cual es un inconveniente.
NOTA: Probablemente haya un número importante de personas que ya hayan descubierto esto hace años, y que yo no esté aportando nada nuevo.
Entonces se me ocurrió una idea: ¿por qué no dividir la lista en listas más pequeñas para lograr esa proporcionalidad? Escribí y testé la siguiente función, a la cual denominé “fast.Reduce”.
[code language=”r”]
fast.Reduce <- function (lista, limite){
l <- length(lista) if (l > limite){
l.2 <- (l %/% 2)
return(rbind(fast.Reduce (lista[1:l.2], limite),fast.Reduce (lista[(l.2+1):l], limite)))
}else{
return(Reduce(f = rbind, x =lista))
}
}
[/code]
La función, recursiva, parte en trocitos la lista para hacer las uniones Reduce más rápido. Admite dos argumentos: la lista de elementos data.frame y un “limite”, que fija el tamaño máximo que una lista tendrá al entrar en la función Reduce; si ésta es mayor que el límite especificado, se parte en dos y cada parte se re-envía a la función. Recursividad básica.
LA PRUEBA
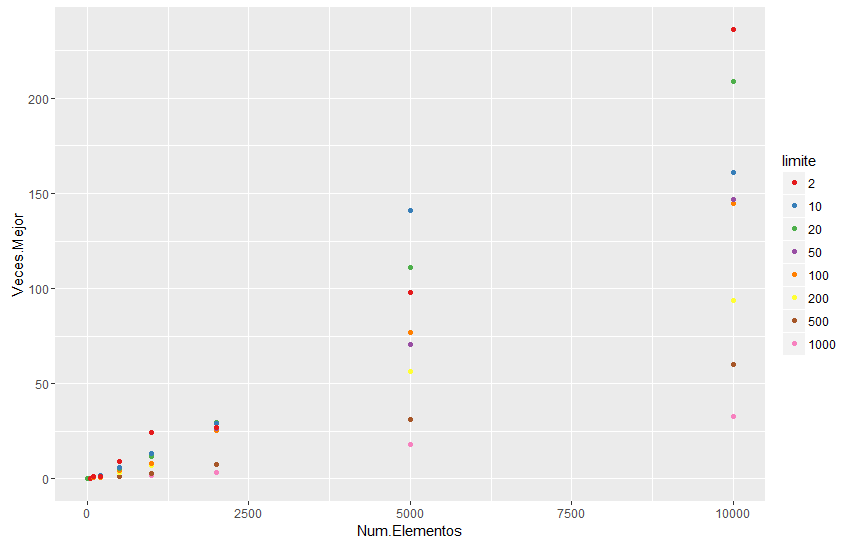
La prueba que hice es la siguiente, y ésta al final devuelve un gráfico en el que se indica cuántas veces es más rápido “fast.Reduce“, para diferentes límites, con respecto a la función Reduce.
[code language=”r”]
# FUNCIONES AUXILIARES —————————————————-
f.CompruebaPaquetes <- function (libRequeridas){
# Comprueba si los paquetes "libRequeridas" están instaladas.
# Si no están instaladas, las instala. Después las carga.
print("Comprobando paquetes …");for (libreria in libRequeridas){if (!any(libreria %in% installed.packages()[,1])) {print(paste0("’",libreria,"’ no está instalado. Se intentará instalar a continuación …’"));install.packages(libreria);if (!any(libreria %in% installed.packages()[,1])) {print(paste0("Por algún motivo el paquete no se ha podido instalar. Compruebe la conexión a Internet o el nombre de la librería (‘",libreria,"’)."));return(libreria);};}else{print(paste0("’",libreria,"’ ya instalado.’"));};print(paste0("Cargando ‘",libreria,"’ …’"));library(package =libreria, character.only = T);};print("Paquetes comprobados y cargados.");return("");};
# FUNCIÓN DE REDUCE RÁPIDO ————————————————
# La función en cuestión. Recursiva.
fast.Reduce <- function (lista, limite){
l <- length(lista) if (l > limite){
l.2 <- (l %/% 2)
return(rbind(fast.Reduce (lista[1:l.2], limite),fast.Reduce (lista[(l.2+1):l], limite)))
}else{
return(Reduce(f = rbind, x =lista))
}
}
# COMPROBACIÓN DE PAQUETES EN R ——————————————-
# Instalar y/o cargar paquetes
f.CompruebaPaquetes(c("ggplot2","stringr"))
# CREACIÓN DE LISTA DE DFs ————————————————
# Crear una lista de ejemplo con muchos data.frame
df <- data.frame(a=rnorm(20), b=rnorm(20), c=rnorm(20), d=rnorm(20), e=rnorm(20))
lista <- list()
for (i in 1:15000){
lista[[i]] <- df
}
# LOG DEL Reduce NORMAL —————————————————
# Generar un registro de tiempos para el Reduce "normal"
tam.lista <- c(10,50,100,200,500,1000,2000,5000,10000)
registro.Normal <- data.frame(Num.Elementos=NA, tiempo.user=NA, tiempo.sys=NA, tiempo.elap=NA)
for (i in 1:length(tam.lista)){
registro.Normal[i,"Num.Elementos"] <- tam.lista[i]
a <- system.time(Reduce(f=rbind, x=lista[1:tam.lista[i]]))
registro.Normal[i,"tiempo.user"] <- a[1]
registro.Normal[i,"tiempo.sys"] <- a[2]
registro.Normal[i,"tiempo.elap"] <- a[3]
print (paste0("Tamaño ",tam.lista[i], " concluido."))
}
# LOG DE LOS Reduce RÁPIDOS ———————————————–
# Generar un registro de tiempos para el fast.Reduce, y para diferentes límites.
limites <- c(1000,500,200,100,50,20,10,2)
registro.Fast <- data.frame(Num.Elementos=NA, limite=NA, tiempo.user=NA, tiempo.sys=NA, tiempo.elap=NA)
contador <- 0
for (i in 1:length(tam.lista)){
for (j in limites){
contador <- contador + 1
a <- system.time(fast.Reduce(lista[1:tam.lista[i]],j))
registro.Fast[contador,"Num.Elementos"] <- tam.lista[i]
registro.Fast[contador, "limite"] <- j
registro.Fast[contador, "tiempo.user"] <- a[1]
registro.Fast[contador, "tiempo.sys"] <- a[2]
registro.Fast[contador, "tiempo.elap"] <- a[3]
}
print (paste0("Tamaño ",tam.lista[i], " concluido."))
}
rm(a, contador, i, j)
# PREPARACIÓN DE CÁLCULOS PARA GRÁFICO ————————————
# Corregir y crear algunas variables
registro.Fast$tiempoNormal <- sort(rep(registro.Normal$tiempo.user, length(limites)))
registro.Fast$Veces.Mejor <- registro.Fast$tiempoNormal / registro.Fast$tiempo.user
registro.Fast$limite <- as.factor(registro.Fast$limite)
# GRÁFICO —————————————————————–
# El gráfico muestra cuántas veces es más rápido fast.Reduce que Reduce,
# dados un número de elementos en la lista y un límite de fast.Reduce.
p <- ggplot(registro.Fast, aes(Num.Elementos, Veces.Mejor)) + geom_point(aes(col=limite)) + scale_colour_brewer(palette = "Set1")
p
# rm (registro.Fast, registro.Normal, lista, fast.Reduce, tam.lista, limites, p)
[/code]
En el gráfico se observa que, cuanto más pequeño es el límite, más rápida es la función. Sin embargo, pienso (esto es una conjetura…) que si el número de elementos en la lista es “demasiado” grande, un límite un poco mayor que 2 puede ser más óptimo (queda pendiente probarlo).
En principio, podríamos dejar la función con un límite predeterminado de 2, y además podríamos parametrizar la función (no tendría por qué ser siempre rbind):
[code language=”r”]
# FUNCIÓN DE REDUCE RÁPIDO ————————————————
# La función en cuestión. Recursiva.
fast.Reduce <- function (lista, fun){
l <- length(lista)
if (l > 2){
l.2 <- (l %/% 2)
return(fun(fast.Reduce (lista[1:l.2], fun),fast.Reduce (lista[(l.2+1):l], fun)))
}else{
return(Reduce(f = fun, x =lista))
}
}
[/code]
LA “CAÍDA”
Hecho y dicho esto, le mostré este hallazgo a un amigo mío que se dedica al Data Science. Tras decirme que el algoritmo estaba muy bien (muchas gracias, por cierto), me desveló que el paquete de R data.table contiene una función específica para hacer esto, y que se llama rbindlist. Ésta tarda apenas unos microsegundos en ejecutarse, aun siendo miles los elementos de la lista…
[code language=”r”]
conjunto.Grande <- as.data.frame(rbindlist(lista))
[/code]
El único inconveniente es que el objeto que devuelve la función es un objeto data.table, que debería ser reconvertido posteriormente en un data.frame (pero tampoco lleva tiempo…).
La moraleja que he sacado de toda esta historia es que:
– Siempre hay que intentar mejorar las cosas y no conformarse con lo que te dan.
– Quizás no conozcas la versión más avanzada de algo y ya esté (mucho más) mejorado.
¡Ciao!
aaaaaaaaayyyyyyyyyyy tonipleite de nuevo peleándose con el rendimiento de R.
Muchas veces me pregunto por qué. R es una herramienta que se utiliza en big data y el rendimiento es… pobre.
Brunch,
R se diseñó hace VARIAS décadas… Es conocido por ser un lenguaje orientado a la estadística, y frecuentemente al tratamiento de datos, pero no es una buena opción para el Big Data. Los 40.000 registros de conjuntos de datos que yo estaba manejando no componen “Big Data” ni de lejos.
Es cierto que el redimiento no es tan rápido como en otros lenguajes, pero las estructuras están construidas, y es fácil de utilizar; no hay que bajarse al nivel de C y estar horas programando.
Ya sabes que todo depende al final del propósito que tengas y de qué rentabilidad se le quiere sacar al programa final a nivel de mantenibilidad y simpleza…
En mi programa tengo una lista con 40.000 pequeños conjuntos de datos, y los uno todos ellos con apenas 30 caracteres. Proponme algo mejor y me lo quedaré para el futuro.
Un abrazo.